
ChatGPT模型參數(shù)是什么意思?ChatGPT中的1750億參數(shù)講解,我們經(jīng)常會看到在介紹大語言、擴(kuò)散等模型時,會在后面或前綴加上100億、500億、2000億等各種參數(shù),你可能會納悶這到底是個啥呀,是體積大小、內(nèi)存上限、還是使用權(quán)限?
在ChatGPT發(fā)布一周年的日子,「AIGC開放社區(qū)」用通俗易懂的方式為大家介紹一下這個參數(shù)的含義。由于OpenAI沒有公布GPT-4的詳細(xì)參數(shù),我們就用GPT-3的1750億來說說。
OpenAI曾在2020年5月28日發(fā)布了一份名為《Language Models are Few-Shot Learners》的論文,就是GPT-3,對模型的參數(shù)、架構(gòu)、功能進(jìn)行了詳細(xì)的闡述。
論文地址:https://arxiv.org/abs/2005.14165
大模型的參數(shù)含義
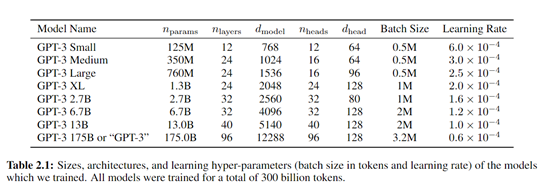
按照該論文的說法,GPT-3的參數(shù)達(dá)到了1750億,而GPT-2只有15億,整整提升了100多倍。
參數(shù)的大幅度提升主要體現(xiàn)在存儲、學(xué)習(xí)、記憶、理解、生成等能力全面得到增強(qiáng),這也是為什么ChatGPT可以無所無能。
這些參數(shù)可以被看作是模型的“記憶細(xì)胞”,它們決定了模型如何處理輸入的數(shù)據(jù)、如何做出預(yù)測和生成文本等所以,大模型中的參數(shù)通常指的是模型內(nèi)部用于存儲知識和學(xué)習(xí)能力的數(shù)值。。
在神經(jīng)網(wǎng)絡(luò)模型中,這些參數(shù)主要是權(quán)重和偏置,在訓(xùn)練過程中通過不斷的迭代來優(yōu)化。權(quán)重控制著輸入數(shù)據(jù)之間的相互影響,而偏置則是添加到最終計(jì)算中以調(diào)整輸出的數(shù)值。
在網(wǎng)絡(luò)層之間的每個連接上都有一個權(quán)重,決定了一個節(jié)點(diǎn)(神經(jīng)元)的輸入在計(jì)算下一個層的節(jié)點(diǎn)輸出時的影響程度權(quán)重是神經(jīng)網(wǎng)絡(luò)中的核心參數(shù),它們表示輸入特征與輸出之間的關(guān)系強(qiáng)度或重要性。。
偏置則是另一種類型的網(wǎng)絡(luò)參數(shù),它們通常與每個節(jié)點(diǎn)的輸出相加以引入一個偏移量,使得激活函數(shù)能夠在零附近有更好的動態(tài)范圍,從而改善和調(diào)整節(jié)點(diǎn)的激活水平。
可以把GPT-3看作是一間超級大辦公室的助理,里面有1750億個抽屜(參數(shù)),每個抽屜里都放著一些特定的信息,包括單詞、短語、語法規(guī)則、斷句原則等簡單來說,。
當(dāng)你向ChatGPT提問時,例如,幫我生成一個用于社交平臺的鞋子營銷文案。GPT-3這個助理就會去裝有營銷、文案、鞋子等抽屜中去提取信息,然后按照你的文本要求進(jìn)行排列組合重新生成。
GPT-3會像人類一樣閱讀大量的文本來學(xué)習(xí)各種語言和敘述結(jié)構(gòu)在預(yù)訓(xùn)練過的程中,。
每當(dāng)它讀到新信息或嘗試生成新的文本方法時,都會打開這些抽屜查看里面的信息,并嘗試找出最好的信息組合來回答問題或生成連貫的文本。
當(dāng)GPT-3在某些任務(wù)上表現(xiàn)得不夠好時,會根據(jù)需要調(diào)整抽屜里的信息(更新參數(shù)),以便下次能做得更好。
所以,每個參數(shù)都是模型在特定任務(wù)上的一個小決策點(diǎn)。更大的參數(shù)意味著模型可以有更多的決策能力和更細(xì)致的控制力,同時可以捕捉到語言中更復(fù)雜的模式和細(xì)節(jié)。
模型的參數(shù)越高,性能就一定越好嗎
從性能上來看,對于ChatGPT等大型語言模型而言,參數(shù)量多通常意味著模型有更強(qiáng)的學(xué)習(xí)、理解、生成、控制等能力。
但隨著參數(shù)的增大,也會出現(xiàn)算力成本高,邊際效應(yīng)遞減,過擬合等問題,尤其是對于沒有開發(fā)能力、算力資源的中小企業(yè)和個人開發(fā)者來說非常困難。
更高的算力消耗:
參數(shù)越大,所消耗的算力資源就越多。這意味著訓(xùn)練更大的模型需要更多的時間和更昂貴的硬件資源。
邊際效應(yīng)遞減:
隨著模型規(guī)模的增長,從每個新增參數(shù)獲得的性能提升越來越少。有時候,增加參數(shù)量并不能帶來顯著的性能改進(jìn),而是帶來更多的運(yùn)營成本負(fù)擔(dān)。
優(yōu)化困難:
當(dāng)模型的參數(shù)量極大時,它可能會遇到“維度的詛咒”,即模型變得如此復(fù)雜以至于很難找到優(yōu)化的解決方案,甚至在某些區(qū)域出現(xiàn)性能退化。這一點(diǎn)在OpenAI的GPT-4模型上體現(xiàn)的非常明顯。
推理延遲:
參數(shù)量大的模型在執(zhí)行推理時通常響應(yīng)較慢,因?yàn)樗麄冃枰嗟臅r間找出更優(yōu)的生成路徑。相比GPT-3,GPT-4同樣有這個問題。
所以,如果你是在本地部署大模型的中小型企業(yè),可以選擇那些通過高質(zhì)量訓(xùn)練數(shù)據(jù)打造的參數(shù)小性能強(qiáng)的模型,例如,Meta發(fā)布的開源大語言模型Llama2。
如果你沒有本地資源希望在云端使用,那么就可以通過API使用OpenAI的最新模型GPT-4Turbo、百度的文心大模型或者微軟的Azure OpenAI、騰訊混元助手等服務(wù),。









 粵ICP備18094028號
粵ICP備18094028號
 粵公網(wǎng)安備 44010602007072號
粵公網(wǎng)安備 44010602007072號